Semantic bridges across research artefacts
How the SemTec team tackels digital silos
Nowadays, data-driven research involves not only data but many other artefacts: software, AI models, training materials, workflows and so on. Whenever these assets are not shared at all or shared with limited metadata, they become digital silos, disconnected and difficult to find.
The Semantic Technologies (SemTec) team at ZB MED tackles this lost-artefacts problem by transforming raw information into a structured, interconnected web of knowledge. In this way, the SemTec team aims at creating metadata bridges along all sorts of research artefacts. The more the better, as far as they are FAIRly linked.
At the core of these bridges lies semantic metadata that provides essential context for any research artefact. The SemTec team uses semantic web standards, e.g. Knowledge Graphs and Resource Description Framework (RDF), to ensure that every artefact is described in a way that any artifact becomes machine-readable, i.e. can be read and processed by machines in a meaningful and FAIR-compliant manner and linked to each other.
The work of the SemTec team drives the implementation of the FAIR principles – findable, accessible, interoperable, reusable. At the same time, it provides a robust semantic and factual infrastructure that can be used for the explainability, reproducibility and transparency of AI.
Research software metadata
Research software is widely used in various disciplines and is often a research object itself. This makes it all the more important to ensure that research software fulfills the FAIR criteria as well. Therefore it must be described with metadata. The CodeMeta Project, an international community initiative, provides the research software community with a basis for describing software-related artefacts. However there are still some limitations to these schemes, such as missing elements or a guidance on how to use CodeMeta, as the NFDI Research Software Metadata Working Group has identified.
- „Research Software Metadata“ – Working Group Charter (NFDI section-metadata): https://doi.org/10.5281/zenodo.10036379
The SemTec team contributes to this effort, which is further advanced by the DFG-funded project Connected Open-Source Software (ConnOSS). ConnOSS started in September 2025 and focuses on developing a knowledge graph-based infrastructure to connect and enhance research software and its corresponding metadata. It is led by ZB MED jointly with GESIS – Leibniz Institute for the Social Sciences and the University of Oldenburg.
Software Management Plans
The SemTec team is also active in the field of software management plans (SMP), which extend standard data management plans to include software-specific requirements. Since 2025, the team has been a partner in the NFDI base project DMP4NFDI, working to integrate SMPs into the Research Data Management Organiser (RDMO). The SemTec team is also participating in a German-based effort to investigate the awareness and use of SMPs.
- „From Vision to Implementation: Current Practices and Challenges of Software Management Plans in Research“: https://doi.org/10.5281/zenodo.16735301
AI models
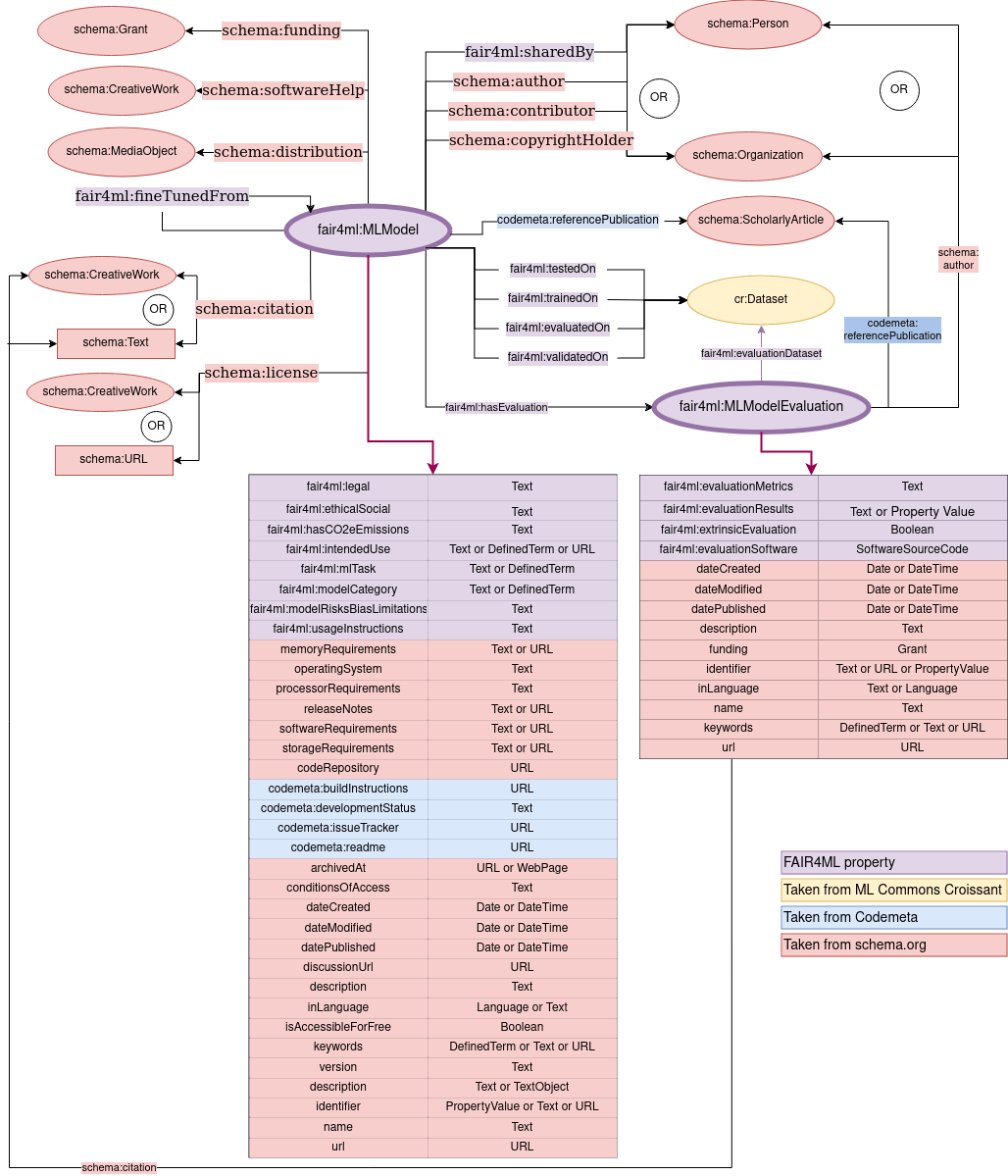
As part of the NFDI4DataScience consortium, the SemTec team is building a registry for AI models: MLentory. MLentory is a comprehensive machine-learning (ML) model discovery platform, currently in pre-beta release. There researchers will find harmonised metadata about AI models so that they can compare models across platforms such as Hugging Face and AI4Life. Further platforms and functionalities are planned. The registry builds on the FAIR4ML metadata schema, a joint effort of the Research Data Alliance FAIR4ML Interest Group.